主成分分析(PCA)
主成分分析法(principal components analysis)其实就是一种降维算法,就是用较少的指标变量去反映出初始数据的大多数信息,这些较少的指标变量就是主成分,这些主成分就是原始变量的线性组合,并且彼此互不相关。主成分分析法主要用来解决多变量且变量之间存在很大相关性的多元分析问题。
基本思想:找到一个坐标轴,将数据映射到这个轴上之后所计算的方差最大,方差越大就意味着点越分散,保留的信息越多,越重要。换就话说,就是从原始数据的一堆变量中提取出一部分变量,这部分变量能尽可能的保留原始数据的特性。例如,将一个三维数据降到两维,就是在一个三维空间找到一个二维平面,将数据投影到平面上,使其在该平面分布的方差最小。
基本步骤:
- 对数据进行中心化(每个特征样本减去均值,把坐标原点放到数据中心)
- 一般情况,第一步直接对数据进行归一化处理(中心化的同时消除量纲的影响)
- 计算归一化后数据集的协方差矩阵与特征值(坐标轴方向的方差)、特征向量(坐标轴方向)
- 选取K个最大的特征值对应的特征向量作为主成分
数据处理
假设有n研究对象,m个指标变量 \(x_1,x_2,\ldots,x_m\) ,第i个对象第j个指标取值 \(a_{ij}\) ,则构成数据矩阵 \(A=(a_{ij})_{n*m}\)
样本均值: $$\mu_j=\frac{1}{n}\sum_{i=1}^na_{ij} $$
中心化: $$ x_j'=x_j-\mu_j$$
归一化: $$ y_j=\frac{x_j-\mu_j}{\sigma_j}$$
其中 \(\sigma_j=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(a_{ij}-u_j)^2}\)
方差
方差是用来度量随机变量和其数学期望(均值)之间的偏离程度的一个统计量。
统计学中(所有样本)的总体方差公式:
$$ \sigma^2=\frac{\sum(X-u)^2}{N}$$
其中\(\sigma^2\)是总体方差,X是随机变量,\(\mu\)是总体均值,N是总体样本数。这里提到的样本,是基于样本数量N(几乎)无限的假设。对应的各个统计量,也是所有的样本所服从的分布的真实参数,是客观正真实的。总体方差是个准确值。
现实情况中,我们往往得不到所有的无限样本,而只能抽样出一定数量的有限样本。通过有限的样本来计算的方差,称为样本方差,公式:
$$ S^2=\frac{1}{n-1}\sum_{i=1}{n}(X_i-\bar X)^2$$
注意上式的系数和总体方差公式里面的系数不一样,分母是n-1。不用n作分母,是因为如果沿用总体方差的公式得到的样本方差,是对方差的一个有偏估计。用n−1作为分母的样本方差公式,才是对方差的无偏估计。样本方差是个随机变量。
协方差矩阵、特征值、特征向量
方差是反映一组数据离散程度的度量,一个维度的方差为:
$$ var(X)=\frac{\sum_{i=1}^n(X_i-\bar X)^2}{n-1}$$
协方差是对两个随机变量联合分布线性相关程度的一种度量,协方差为0,证明这两个维度之间没有关系,协方差为正,两个正相关,为负则负相关。定义为:
$$ cov(X,Y)=\frac{\sum_{i=1}^n(X_i-\bar X)(Y_i-\bar Y)}{n-1}$$
标准化后的数据矩阵 \(B=(b_{ij})_{n*m}\) ,样本矩阵:
其中 \(b_{ij}=\frac{a_{ij}-\mu_j}{\sigma_j}\) ,均值为0,标准差为1.
协方差矩阵
注意:
1、协方差矩阵是对称矩阵,对称矩阵的特征向量相互正交,其点乘为0。
2、数据点在特征向量上投影的方差,为对应的特征值,选择特征值大的特征向量,就是选择点投影方差大的方向,即是具有高信息量的主成分。次佳投影方向位于最佳投影方向的正交空间,是第二大特征值对应的特征向量,以此类推。
特征值、特征向量
相关系数矩阵就是随机变量标准化后的协方差矩阵,计算相关系数矩阵R=\(\Sigma\) 的特征值和特征向量
\(R\alpha=\lambda\alpha\),\(\lambda\) 为特征值,\(\alpha\) 为特征向量
因此,得到相关系数矩阵R的特征值\(\lambda_1,\lambda_2,\ldots,\lambda_m\), 及对应的标准正交化特征向量\(\alpha_1,\alpha_2,\ldots,\alpha_m\) ,其中\(\alpha_j=[\alpha_{1j},\alpha_{2j},\ldots,\alpha_{mj}]^T\) ,由特征向量组成m个新的指标变量
其中\(F_1是第1主成分,F_2是第2主成分,...,F_m是第m主成分\)
贡献率、累计贡献率
主成分\(F_j\)的贡献率为:
$$ w_j=\frac{\lambda_j}{\sum_{k=1}^{m}\lambda_k} , j=1,2,\ldots,m$$
前i个主成分的累计贡献率为:
一般取从大到小排序累计贡献率达到85%以上的特征值\(\lambda_1,\lambda_2,\ldots,\lambda_k\),所对应的前k个主成分\((k\leqslant m)\),即将数据从m维降到k维,达到降维的目的。
利用sklearn库实现PCA
import numpy as np
from sklearn import decomposition
np.random.seed(0)
x1 = np.random.normal(size=100) #默认均值0,标准差1的正态分布,shape=(100,)
x2 = np.random.normal(size=100)
x3 = x1 + x2
X = np.c_[x1,x2,x3] #(100,3)
pca = decomposition.PCA() #也可以直接添加n_components参数
pca.fit(X)
print(pca.explained_variance_) #可解释性方差(特征值)
pca.n_components = 2 #设置维度
X_reduced = pca.fit_transform(X)
print(X_reduced.shape)
输出:
[3.51511512e+00 9.35139697e-01 1.40645385e-31]
(100, 2)
手动实现PCA
import numpy as np
from sklearn import decomposition
np.random.seed(0)
x1 = np.random.normal(size=100) #默认均值0,标准差1的正态分布,shape=(100,)
x2 = np.random.normal(size=100)
x3 = x1 + x2
X = np.c_[x1,x2,x3] #(100,3) ,除一维数组外,和np.hstack结果相同
n,m = X.shape
mean_c = np.mean(X,axis=0) #每一列均值
std_c = np.std(X,axis=0,ddof=0) #总体方差ddof=0,sigma:除以n;样本标准差ddof=1,sigma:除以n-1;方差用np.var
std_data = (X-mean_c)/std_c
sigma = 1/n*np.dot(std_data.T,std_data) #协方差矩阵(相关系数矩阵)
#计算特征值、特征向量
eig_vals,eig_vecs = np.linalg.eig(sigma)
#特征值和特征向量配对
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
# 按特征值大小进行排序
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# 指定要降到的维数,比如2。将特征向量水平平铺合并,以列向量形式拼合。
pca_matrix = np.hstack([eig_pairs[i][1].reshape(-1, 1) for i in range(2)])
# 将原始数据进行投影。
res = X.dot(pca_matrix)
print(sorted(eig_val,reverse=True))
print(res.shape)
输出:
[2.1117041069332574, 0.8882958930667454, 4.532663311939432e-17]
(100, 2)
正交矩阵
定义:A是正交矩阵,则A必为方阵,并且 \(AA^T=E\)或\(A^TA=E\) ,E是单位矩阵。
特征:
- \(A^T的各行是单位向量且两两正交\)
- \(A^T的各列是单位向量且两两正交\)
- 行列式detA=+1或-1
- \(A^T=A^{-1}\)
- 正交矩阵一般用字母Q表示
- 例如\(A=[r_{11},r_{12};r_{21},r_{22}]\) ,则:\(r_{11}^2+r_{12}^2=r_{21}^2+r_{22}^2=1\),\(r_{11}r{21}+r_{12}r_{22}=0\)
奇异值分解(SVD)
吴恩达的《机器学习》课程中的主成分分析的视频中,采用的是协方差矩阵\(\Sigma\) 的奇异值分解(SVD)来减少计算量,而上述我们采用的是协方差矩阵的特征值分解的形式求解,其本质是一样的,因为协方差矩阵是对称正定的。
对于对称正定矩阵A,其特征值分解:\(A\alpha=\lambda\alpha\)
它的奇异值分解:\(AA^T\alpha=A\lambda\alpha=\lambda^2\alpha\)
奇异值分解(Singular Value Decomposition)定义:
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
$$ A=U\Sigma V^T$$ 其中U是一个m×m的矩阵,\(\Sigma\) 是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足\(U^TU=I,V^TV=I\).(若酉矩阵的元素都是实数,即为正交矩阵)。
求U: 求\(AA^T\)的特征向量得到一个m×m的方阵,对该方阵进行特征分解,得到\(AA^T\)的m个特征值和对应的m个特征向量,将所有特征向量张成一个m×m的矩阵,即U矩阵。一般我们将U中的每个特征向量叫做A的左奇异向量。
求V: 求\(A^TA\)的特征向量得到一个n×n的方阵,对该方阵进行特征分解,得到\(A^TA\)的n个特征值和对应的n个特征向量,将所有特征向量张成一个n×n的矩阵,即V矩阵。一般我们将V中的每个特征向量叫做A的右奇异向量。
求\(\Sigma\): 由于\(\Sigma\)除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值\(\sigma\)就可以了。
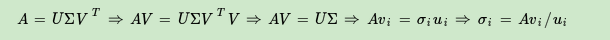
如上,求出每个奇异值,按对角线排列得到奇异值矩阵。
也可以通过求出\(A^TA\)的特征值取方根来求奇异值,\(\sigma_i=\sqrt{\lambda_i}\)。
def _svd(data):
U, S, VT = np.linalg.svd(data)
return U, S, VT
参考:
https://zhuanlan.zhihu.com/p/29846048
https://zhuanlan.zhihu.com/p/78193297 平